Concepts
 A mesh network or database works by systems loosely talking between themselves in a some what random
fashion. Much the same way you might tell close friends that you are pregnant, and this message will generally
diffuse among everyone you know over time1. A mesh database works in a similar way, but with a few more constraints
to both ensure faster message delivery and also reduce message clutter.
A mesh network or database works by systems loosely talking between themselves in a some what random
fashion. Much the same way you might tell close friends that you are pregnant, and this message will generally
diffuse among everyone you know over time1. A mesh database works in a similar way, but with a few more constraints
to both ensure faster message delivery and also reduce message clutter.
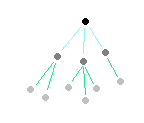
A logical structure is applied on top of the mesh network, which applies a hierarchy of parent/child systems. This means one system can be designated the logical master, with sub masters and eventual worker systems. This structure is only used to aid understanding and workers can communicate directly to other workers without centralised master servers.
With this structure, the "top" system is called the "authority". It communicates down to the next layer, and that layer communucates to either another layer, or workers.
In a retail environment this loosely translates to each lane in the store communicating to a store server, which in turn talks to head office and/or cloud based systems. However, the actual communication will use multiple paths for reliability. So checkout lanes in one store may communicate directly to a lane in another store as well as it's designated store server. This approach ensures that any single failure is unlikely to cause wide spread disruption.
Note 1. "Time" does not imply slow for the database, urgent data can be replicated to other systems immediately, and most non critical data is available within a few seconds, it has been intentionally slowed down to save network traffic costs.
Space and Performance Considerations
With a mesh structure, each node is likely to hold more a considerable amount of data locally. Not all this data is required but is being held as redundant copies.
Using Automatic Replication
By default systems will use automatic replication. With this mode you there is typically not much setup involved. When installing a system for the first time you need to authorise it by connecting the security key to the system. This action also preloads a number of known systems in the network. From this point on the machine will communicate to some of the systems in this list and any others discovered over time.
A exception for automatic replication relates to communicating to external systems on the internet (such as a selling point at a street carnival), where you will need to explicitly enable a system to communicate to the internet general population. Data is encrypted for all communication, internal and internet
Using Manual Replication
You can configure systems to use manual replication to take advantage of cloud based file sharing sites such as Dropbox, SkyDrive (Trademarks) or any other service that permits you to replicate files from one system to another. You only need to use manual replication when using systems that cannot automatically discover each other or routes between systems.
Quick Key Points:- Fieldpine creates a number of output log type files that should be replicated to other systems. You control which systems files are sent too as well as how files are moved.
- Files are to be considered "random binary data" and do not have a documented structure.
- Files are compatiable across different architectures and operating systems already, do not apply any transformations to the delivered output files.
- You do not need to be overly concerned about which files go where, the system itself handles many of these types of issues.
- Files are typically already encrypted
Operational Description
This section contains a conceptual overview on how mesh data is stored but it is provided to aid understanding, it should not be relied on as the accurate technical description.
- Data is stored in groups of objects. Generally these objects are directly tabular and are very similar to relational database tables. There is "products" set of objects which can be considered to be equivalent to a SQL "product" table. Some objects however are able to store in more object form, such as sales which might store using an internal parent/child structure.
- Each object type (eg products or sales) is responsible for it's own family. The products objects determine what is stored and also rules for replication.
- For simple reference data, like products, you should expect to see all rows sent to all nodes. Logs and other information that is not globally interesting will probably only be sent "up" to higher valued servers, rather than "across" or "down" to end systems.
- Mesh programs are in two main classes, full and partial. Full programs are able to fully understand structures and rules and be active members in the network. Partial programs perform less processing and typically request current data at periodic intervals.
- Mesh data files will be stored in the same directory as the original Access database. You need both the Access database and the mesh files. This means that a shared database configuration will continue to use shared mesh data files.
- Mesh data files have long complex filenames. This name is important and you should preserve it. The files are named in such as way that you can freely copy them around with risk of conflict or causing corruption.
When the POS reads a record using Mesh database, it opens the current reference file and extracts the data/records it wants. If the files do not exist it might request data from other nodes in the network
When the POS writes a record into the Mesh database, it applies the change to its current reference files (these are shared in some cases) and queues the record for offsite transmission. These offsite queue files are stored on each node, not in a central area
A sync operation can be performed at any stage, but is not often required